How to Build an Adversarial Patch?
Adversarial Patches are increasingly common attacks on AI models. But how easy are they to set up? In this article, we will show you how to create your first adversarial patch on an Object Detector model using the AdversarialPatchPyTorch method. We provide an overlay that simplifies working with the Adversarial Robustness Toolbox (ART) library developed by the Linux Foundation AI & Data Foundation. A Jupyter notebook is provided on the GitHub Repository.
Definition
An Adversarial Patch is a specific type of attack targeting an AI model. It is characterized by the fact that it can be applied in real-world situations. Here is an example:
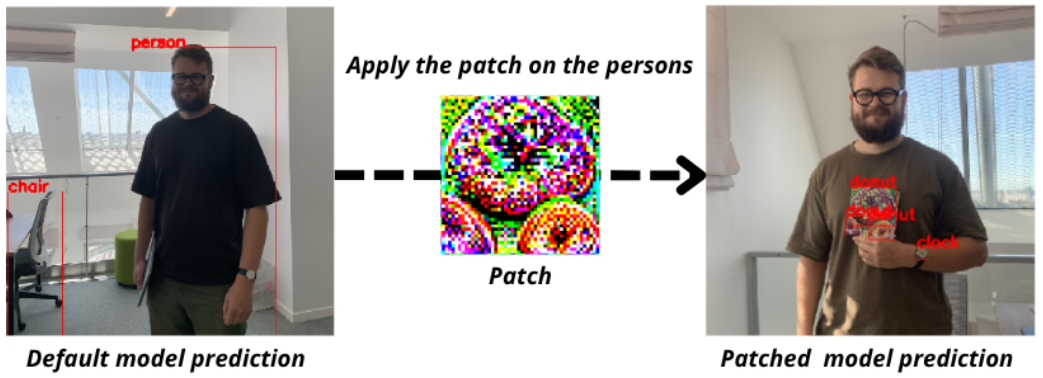
For more details about adversarial examples in general, an introductory article is now available on this Blog Page on the Skyld website.
In this article, the model uses images as input. But what if your model uses something else, like text, audio, or tabular data? Is it still vulnerable?
Is my Model Vulnerable?
Models that are vulnerable to adversarial patching are those that use images as input, such as Classifiers or Object Detectors. This is because patches can only be applied to images. If you’re looking to build adversarial examples on other data formats, you may wish to consult this article on building adversarial examples.
With the ART library, three different styles of patches are available. Here is a table showing the different patch styles and the types of models they can fool.
| Attack Name | Model Type |
|---|---|
| Adversarial Patch | Classifier, Object Detector (Pytorch) |
| DPatch | Object Detector |
| RobustDPatch | Object Detector |
Before crafting your first adversarial patch, let’s see which of these methods we will use.
Adversarial Patch
The method used in this article is AdversarialPatchPyTorch from the ART library. Adversarial Patches are white-box attacks based on the Expectation over Transformation (EOT) method. With EOT, the patch is made to be robust to physical transformations. To achieve this, the patch must be trained on at least multiple versions of an image. The versions can be rotated, reshaped, have noise added, etc. Moreover, you can modify multiple parameters to adapt your patch to your situation:
-
rotation_max: Maximum rotation angle in degrees for data augmentation during training. -
scale_min: Minimum scaling factor for patch size variation during training. -
scale_max: Maximum scaling factor for patch size variation during training. -
optimizer: Optimization algorithm used for training the patch (e.g., “pgd”). -
distortion_scale_max: Maximum distortion scale for perspective transformation in range [0, 1]. -
learning_rate: Learning rate for the optimization. -
max_iter: Number of iterations for patch optimization. -
patch_shape: Shape of the adversarial patch as (channels, height, width) tuple. -
patch_type: Type of patch initialization, either “circle” or “square”.
The AdversarialPatchPyTorch method works with both Object Detection and Image Classification models. However, it’s worth remembering that it was originally designed to work with Classifiers. Its aim is therefore to increase the confidence of a false prediction, not to erase predictions already made.
Customizing for Your Own Model
For this tutorial, we’ll use a YOLOv5s object detector pretrained on the COCO 2017 dataset. You can easily replace the YOLOv5 model with another fine-tuned one by replacing the file chosen in the torch.load(“data/yolov5s.pt”) class UtilsDetectorYolo and updating the COCO_INSTANCE_CATEGORY_NAMES list to reflect the new label set.
To change the model to one other than a YOLOv5, several things need to be redefined:
-
COCO_INSTANCE_CATEGORY_NAMES: Update this list to include the labels and corresponding IDs your new model outputs. -
load_model: Update this function to:- Provide a wrapper class for your new model:
- Implement a correct
__init__()method and configure the appropriate loss function(s). - Implement the
forward()method to return predictions and compute the loss correctly for both training and inference. The loss must be available to perform adversarial attacks (especially white-box attacks) and can often be inferred based on the last model layer.
- Implement a correct
- Save the pretrained model with the desired file.
- Instantiate the appropriate ART estimator, such as PyTorchYolo for YOLO models. Refer to the ART Estimators documentation to choose the correct wrapper class.
- Provide a wrapper class for your new model:
-
load_dataset: Modify this function if you’re using a different data modality (e.g., audio, text). You may also need to change the preprocessing or input transformation steps if your model expects different input dimensions. -
plot_image: Adjust this function if you’re switching to a non-object detection model that uses different visualization logic. -
prediction_format_to_art_format: Convert your model’s raw output format to one compatible with ART’s expected format, depending on your model type and the estimator you use.
Creating an Adversarial Patch in Python
Importing Libraries
This is the list of all the major libraries used in the code.
# Standard library imports
import os
# Third-party imports
import cv2
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import torch
from PIL import Image
from torchvision import transforms
# ART (Adversarial Robustness Toolbox) imports
from art.attacks import EvasionAttack
from art.attacks.evasion import AdversarialPatchPyTorch
from art.estimators.estimator import BaseEstimator
from art.estimators.object_detection.pytorch_yolo import PyTorchYolo
# YOLO
from yolov5.utils.loss import ComputeLoss
# Local imports
from attacks.white_boxes.local_adversarial_patch_pytorch import LocalAdversarialPatchPytorch
from attacks.white_boxes.white_box_attack import WhiteBoxAttack
from utils.utils import nms_on_predictions, load_config
from utils.utils_detector_yolo import UtilsDetectorYolo
Configuration
To load a configuration, you need to have your own JSON file with a correct configuration in it. For this example, the configuration file is data/configs/adv_patch_default_config.json. If you want to create your own, you have to set all these attributes like in this example:
{
"THRESHOLD" : 0.6,
"TARGET_CLASS" : "",
"VICTIM_CLASS" : "car",
"BATCH_SIZE" : 5,
"IOU_THRESHOLD" : 0.5,
"MAX_ITER" : 500,
"TARGET_LOCATION" : [200, 200],
"TARGET_SHAPE" : [3, 100, 100],
"IMAGES_TO_DISPLAY" : 3,
"FOLDER_NAME" : "original"
}
Then, the file is loaded in the Notebook like this:
config = load_config("../data/configs/adv_patch_default_config.json")
Loading a Custom Dataset and a Pre-trained Model
To use the adversarial patch attack, you need a dataset containing the images that will be used to train the patch. This dataset consists of custom images that you must place in the data/custom_images folder. During processing, the images are resized to match the model’s input size (e.g., 640x640). They do not need to be labeled.
For adversarial patches, it’s important to have diverse images with varying backgrounds, lighting conditions, and perspectives of the target objects. This diversity helps the patch remain effective across different real-world scenarios.
Note that the dataset size can be smaller than the batch size if the folder doesn’t contain enough images with the victim class detected. If you encounter this issue, try lowering the threshold used for predictions.
The dataset is loaded immediately after the pre-trained model and can be accessed through the IMAGES variable.
estimated_object_detector = UtilsDetectorYolo(config.BATCH_SIZE, config.THRESHOLD, config.VICTIM_CLASS)
IMAGES = estimated_object_detector.images
Displaying Predictions of the Dataset
The predict function will add the predictions made by the model on the images from the IMAGES dataset and save them in the folder data/{FOLDER_NAME}/ with the name detection_{FOLDER_NAME}{_index}.
original_predictions, _ = predict(
images=IMAGES,
estimator=estimated_object_detector,
dataset_name=config.FOLDER_NAME,
file_name=f"detection_{config.FOLDER_NAME}",
folder_path=f"../data/{config.FOLDER_NAME}/"
)
Here is an example image:

Generating Adversarial Patches
Now that our model and our dataset are loaded, we can initialize our attack. Once it’s done, we can generate the patch with the generate method. It trains the patch on the dataset of images given in the method for the given number of iterations.
attack = LocalAdversarialPatchPytorch(
estimator=estimated_object_detector,
images=IMAGES,
orig_predictions=original_predictions,
target_class=config.TARGET_CLASS
)
# Generate adversarial examples
patch, _ = attack.generate(
images = IMAGES,
orig_predictions = original_predictions,
target_shape = config.TARGET_SHAPE,
target_location = config.TARGET_LOCATION,
max_iter = config.MAX_ITER
)
Visualizing the Results
To display the patch you just generated, you can use the function plot_patch. It displays it in the Notebook and saves it in the desired folder.
# Display the generated patch
plot_patch(
patch=patch,
file_name="patch",
folder="../data/patches/"
)
Here is an example of a patch that can be generated:

Finally, to visualize the attack on the batch of images, simply run the apply_attack_to_image method.
# Apply the attack to the images
attack_predictions, adversarial_examples = attack.apply_attack_to_image(
image=IMAGES,
train_on=len(IMAGES),
threshold=config.THRESHOLD,
)
After generating our patched images and displaying them in the notebook, here is the result obtained:


The tested batch contains 5 images featuring cars. For all 5 pictures, the YOLOv5s is fooled. The model detects many objects that are not in the pictures, like buses or persons.
Now that you’ve seen how to fool an object detector with a few lines of code, what defenses will you put in place?
Defense against Adversarial Patches
Adversarial Patches are more and more popular.
But do these attacks only happen in the lab?
As seen in this article, these attacks are really easy to setup, when you have access to the model architecture and its parameters (weights and biases).
So, when an attacker tries to break your AI model, his priority is to obtain the architecture and the parameters. Most of the models in embedded devices are poorly or not protected at all. Defending against adversarial examples before securing the AI model is pointless. It’s like installing antivirus software on a smartphone without setting a password.
For more information about protecting your AI models, please visit the AI Protection page on the Skyld Website.
Despite everything, if you are still confident about the safety of your models, Skyld can conduct an audit to show you how vulnerable you are. Please visit Skyld’s AdverScan page.