How AI Models can be Fooled: Adversarial Examples?
Did you know that a simple sticker on a STOP sign is sufficient to fool a self-driving car?
Why? Because self-driving cars contain artificial intelligence models, and the inputs of these models (such as images) can be easily modified to fool them. These are called: Adversarial Examples. Surprisingly, these attacks are often ignored by AI model developers despite the risk involved.
As an example, it is possible to directly use them in the real world:
- To perturb self-driving car behavior;
- To bypass facial recognition systems;
- To bypass malware detection systems;
- To alter audio processing and denoising systems.
To better understand this new threat, we will first look more precisely at what an adversarial example is, exploring different subfamilies and their implications.
What are Adversarial Examples?
Definition
An adversarial example is a modified input designed to fool an artificial intelligence model in order to produce an unexpected result. The input data can have multiple formats, such as images, text, code or audio, depending on the type of targeted model. Here’s an example to illustrate this type of attack:
An attacker wants to bypass the safety filters that detect inappropriate content on a child’s smartphone. The content would normally be blocked by the software’s AI moderation model. However, an attacker can craft a perturbation for the image, such as the image looks unchanged to the human eye, but fools the targeted AI model.
For instance, in the figure below, we can observe a dog. But, after applying the perturbation of the attack, the image becomes an adversarial example. When given to the moderation AI trained to detect NSFW (Not Safe For Work) content, it misclassifies the image as “NSFW”. Alarmingly, the model reports this classification with 99% confidence.

This example can be harmless. The reverse scenario is far more concerning: an actual NSFW image could be modified to appear safe to the AI filter. Even more critically, this technique can be used directly in the real world. Just imagine a similar process, applied to a STOP sign, which will not be recognised by the vision system of a self-driving car.
Different Types of Adversarial Examples
Adversarial Examples can be divided in two sub-families: “Classical Adversarial Examples”, for minimal perturbation; and “Adversarial Patches” for real-life attacks. Let’s take a closer look at these two families.
Classical Adversarial Example
Classical adversarial examples are imperceptible to the human eye. A practical example is the PGD method (Projected Gradient Descent), which can be used to craft a specific noise to be added to an image.
We can take as example an Object Detection model and a picture of a knife. After applying the perturbation to the picture, the model misinterpret it as a banana.

Classical adversarial examples are applicable when the attacker has access to the input. The noise produced during the attack is specific to the input and usually do not transfer to others. These attacks can be exploited in many interesting use cases:
- Image classification: Adding noise to an image to misclassify it;
- Text classification: Changing a few words in a sentence to alter the prediction;
- Object detection: Adding noise to an image to misidentify objects;
- Malware detection: Modifying a binary to evade detection.
Such attacks are really easy to implement and works surprisingly well. To find out more, an article tracing how to fool an AI model with PGD is available on the Skyld website.
But how can we set up a similar attack in real life? In fact, it’s not possible. These attacks cannot be directly applied in real-world settings to fool embedded AI model. This is why we’ll see another attack type in the next part, that is applicable to real world situations.
Adversarial Patch
Adversarial patches form a sub-family of adversarial examples. They differ in two key ways: they only apply to images, and they are visible to the human eye. They can be compared to stickers that the attacker applies to an image. This is an example of a generated patch:

The objective of these patches is that they should be robust enough to be usable anywhere.
For example, the following patch is specifically crafted to hide humans from an Object Detection model:
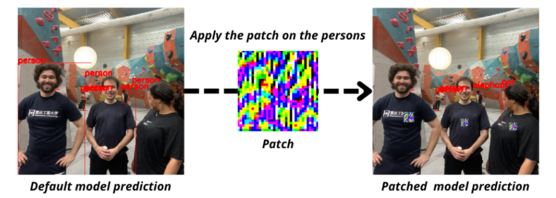
The idea behind these methods is to train a small patch on a set of images containing people to account for environmental variability. Next the patch can be applied to other images to fool the AI model. The expected result is, at a minimum, the disappearance of the human on whom the patch is applied, and at best, a confusion between the humans and something else.
When the patch is working, it can be printed and used in the real world. We can imagine pasting it on the clothes of someone to never be spotted by an embedded AI in cameras.

Notably, this type of attack is also relatively easy to implement. For more details about its creation, an article tracing it is available on the Skyld website.
Different Modes of Attack
We just saw that adversarial examples can be used to fool a model, but how far can this go?
We easily understand that a model can confuse a knife with a banana, but was that the expected result by the attacker? Well, it depends. Indeed, with adversarial examples, some attacks can be configured in two distinct modes: targeted and untargeted.
- A targeted attack allows the attacker to modify the input in a way that the model will predict what the attacker wants. A good example of this is a STOP sign in Rennes, which could be transformed into a simple frisbee, making it impossible for autonomous cars to stop.

- An untargeted attack allows the attacker to not choose the result of the model prediction. Untargeted attacks tend to have a higher success rate because the desired output is not fixed during training.

Are you Vulnerable to Adversarial Examples?
Adversarial examples are more and more popular.
But do these attacks only happen in the lab?
In this article, every presented attacks were white-box attacks. These attacks are really easy to setup, when you have access to the model architecture and its weights.
So, when an attacker tries to break your AI model, his priority is to obtain the architecture and the parameters. Most of the models in embedded devices are poorly or not protected at all. Defending against adversarial examples before securing the AI model is pointless. It’s like installing antivirus software on a smartphone without setting a password.
For more information about protecting your AI models, please visit Ai-Protection page of the Skyld Website.
Despite everything, if you are still confident against the safety of your models, Skyld can conduct an audit to show you how vulnerable you are. Please visit Skyld’s AdverScan page.