When On-Device AI Becomes a Security Flaw: The SafetyCore Case Study
Artificial intelligence is increasingly embedded within everyday devices. Smartphones, IoT gadgets, and vehicles now run AI models directly on the device, without relying on cloud infrastructure. This trend, known as on-device AI, brings clear advantages: improved data privacy and reduced latency. However, it also introduces a new and often overlooked attack surface.
At Skyld AI, we recently conducted a case study on SafetyCore, a Google systems service that embed an on-device AI model for sensitive image content detection. Our analysis demonstrates how attackers can extract and manipulate the AI model, effectively bypassing its utility.
SafetyCore: Android’s Sensitive Content Filter
Since late 2024, Google has integrated SafetyCore into Android. This system component is designed to detect sensitive or explicit content within images sent through Google Messages. When such content is identified, the system automatically applies a blur and displays a warning message to the user.
To protect user privacy, the model runs locally on the device rather than on Google’s servers. While this design choice avoids the transfer of personal data, it also makes the model directly accessible to anyone with physical access to the device.
Extracting the Model
Unlike traditional software, AI models are stored in standardized file formats (such as TensorFlow Lite, ONNX, or TorchScript) that include their structure and learned parameters. This makes it possible to locate and extract them using static analysis techniques.
In the case of SafetyCore, our team analyzed the system files and identified a TensorFlow Lite model using its distinctive TFL3 file signature. This allowed us to extract the model without executing the application. Even if encryption had been used, known techniques such as runtime interception with tools like Frida could have been applied to recover the model from memory.

Converting the Model for Analysis
After extraction, the model was converted into a format suitable for security testing, in this case PyTorch. Although the model was quantized to int8 to reduce its size, we were able to reconstruct a float32 version using the quantization parameters. This reconstruction allowed us to create a fully differentiable proxy model that accurately replicated the behavior of the original SafetyCore model.
Exploiting Model Vulnerabilities
Using the proxy model, we applied a standard adversarial attack technique known as Projected Gradient Descent (PGD). This method involves adding imperceptible perturbations to input images to deliberately mislead the model.
We demonstrated two attack scenarios:
- Triggering false positives: Benign images can be perturbed in a way that causes the model to classify them as explicit, leading to unnecessary blurring.
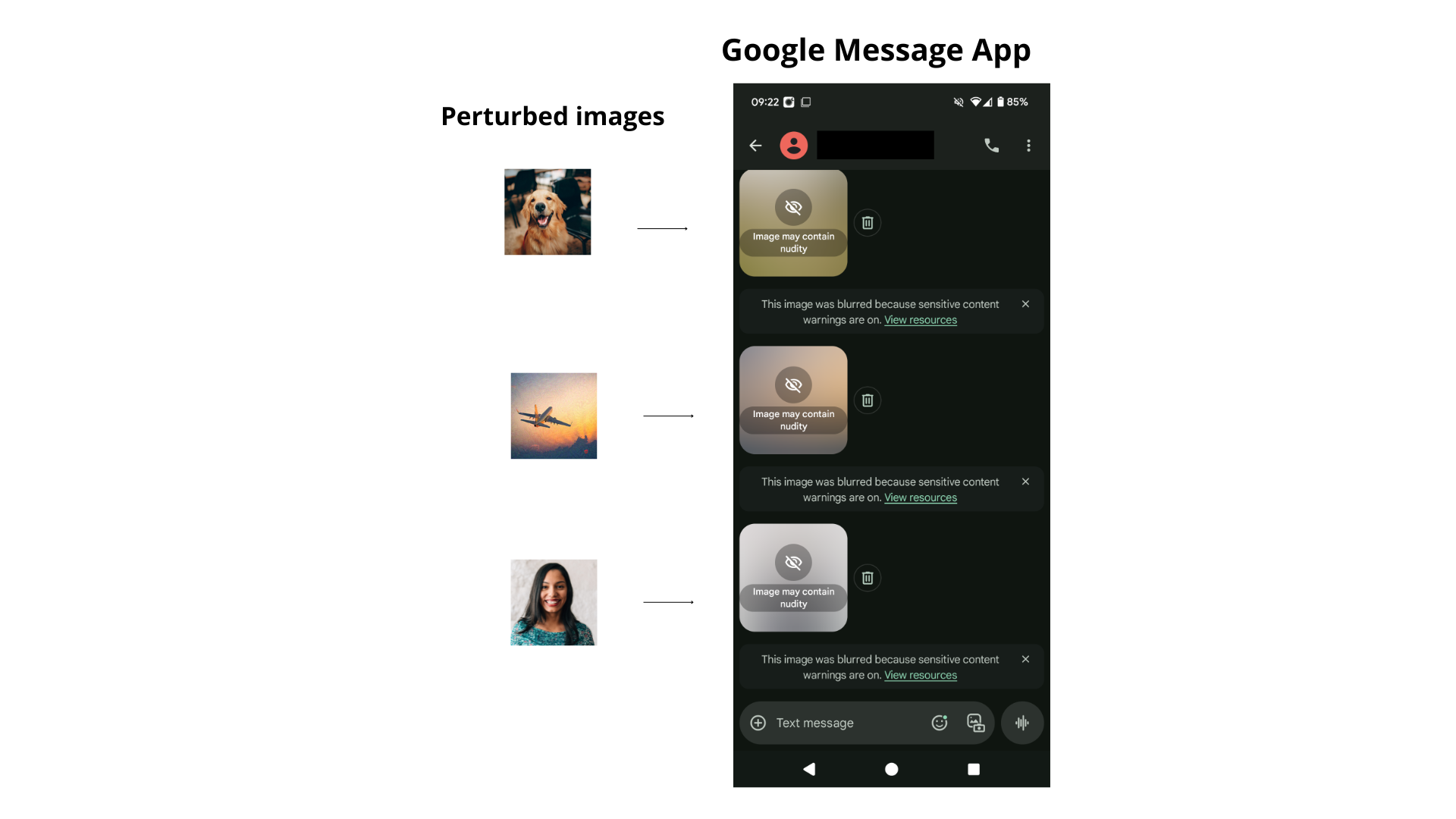
- Bypassing blurring: Explicit images can be subtly modified so that the model fails to recognize their content, resulting in no blur being applied.
Both scenarios can be achieved with fewer than 30 lines of code. Because the same SafetyCore model is distributed across all Android devices, these attacks are reproducible at scale.
Key Takeaways
This case study highlights the unique security challenges posed by on-device AI. Traditional defenses such as encryption, or obfuscation, are not sufficient to prevent model extraction and exploitation. Once an attacker has access to the model, it can be treated as a mathematical object and systematically attacked.
For systems intended to protect users, such as content filters, spam detectors, or fraud detection models, the implications are significant. Compromised models undermine user protection and trust at scale.
Conclusion
On-device AI represents an important technological advancement, but it also requires a dedicated security mindset. The SafetyCore case demonstrates that embedded AI models can be extracted and bypassed with relative ease.
At Skyld AI, we believe model security must be treated as a core component of AI system design. This includes hardening model deployment, monitoring for exploitation, and developing robust defenses that go beyond traditional software protection mechanisms.
Source: Guyomard V., Mauvisseau M., Paindavoine M. (2025). Breaking SafetyCore: Exploring the Risks of On-Device AI Deployment. Skyld AI.
For more information about protecting your AI models, please visit the AI Protection page on the Skyld Website.
Despite everything, if you are still confident about the safety of your models, Skyld can conduct an audit to show you how vulnerable you are. Please visit Skyld’s AdverScan page.




